中国新媒体(http://www.zhgxmt.cn):微博事件的新闻线索发现
摘要:一个网络事件的发生常常引起大量用户在互联网上的评论,而如今很多网络事件是新闻线索的源头。本研究利用CRF等信息识别方法及技术,通过对微博平台上事件的事件触发词、命名实体、时间表达和事件后果进行信息识别,从而挖掘出事件中的新闻线索,并对结果进行了可视化界面的展示。本研究的成果有助于支撑新闻媒体在微博平台上快速发现新闻线索,把握事件发展方向。
关键词:新闻线索 事件挖掘 信息识别
1. 前言
新闻线索发现从技术角度来看是一个事件挖掘任务。事件挖掘就是从大量的、不完全的、人们事先不知道的,但同时又是潜在有用的信息中提取有用信息并概括为事件的过程。对事件挖掘的任务进行形式化的定义:D为数据集来源上的数据文档,E为经过事件挖掘得到最终事件的描述。D是待处理的源数据,E为最终挖掘出的事件集合,则事件挖掘就是如下的映射过程ξ:D→E。
本研究选取了国内事件影响力较大、用户活跃度较高的中文微博作为事件源头平台,从微博平台上搜索关键词爬取得到事件微博。分别对事件的四个主要信息进行了提取:事件触发词、命名实体、时间表达和事件后果进行信息识别。其中,运用了CRF工具对事件触发词及命名实体进行了识别,通过规范化处理对事件的时间表达进行了抽取,最后用基于规则匹配的算法对事件后果进行了抽取。
2. 国内外研究现状
国外对于事件挖掘技术的研究开始较早。1996年,为了更好地解决网络背景下事件的提取问题,美国国防高级研究计划局(DARPA)提出了话题检测与跟踪(Topic Detection and Tracking)即TDT任务。早期TDT的早期研究代表人物是Allan(1998)和Lam(2001)。Allan提出了基于单路径聚类的话题识别算法。该算法关注文档与文档之间的相似度,没有从事件的角度展开研究。随着事件的发展,同一事件可能会因为报道侧重点的不同而被定义为不同的事件,该方法有较高的误判率。Lam提出基于事件的话题识别算法,将每个新闻类看作一个事件,同Allan的方法一样,Lam的方法的精度仍有待提高。这些初步的研究为后续的TDT研究奠定了基础。
已有的TDT方法包括:基于命名实体方法(Yang, 2002; Kumaran, 2004)、增量式TFIDF模型(Brants, 2003)、基于语义链的方法(Ulli Waltinger, 2008)、除了上面介绍的基于聚类、权值计算、命名实体、语义链等方面的方法改进外,最新的研究趋势一是将拓扑结构知识融入事件挖掘中,如Robert Ghrist(2008)等人提出了应用不变同调的理论来对点云数据进行拓扑聚类;二是将探讨传统方法在新的数据环境下的改进。如Petrovi?等(2010)提出了一种基于局部敏感哈希的算法来进行twitter中的新事件发现,来克服传统方法的不足。Hovy(2012)也针对twitter进行了结构化事件信息抽取的研究。值得注意的是Ritter等(2012)将twitter中的事件挖掘分解成了三个子任务,并分别提出了基于twitter数据的训练模型,有效避免了噪声和其他因素的影响,得到了很好的结果。
国内研究现状同国外在事件挖掘领域研究相似的是国内的最新研究也主要是在命名实体(张阔,2008)、以及文本的表示(洪宇,2008)和语义链等方向上进行的改进研究。在语义链方向,Wang(2009)等人提出将文档结构和语义特性结合来提取重要词语和文档聚类,并且将传统的语义聚类模型进行了改进,对标题、关键词和摘要的相似度进行单独计算并考虑到聚类模型之中。Qiu(2008)等人用DSLM(Dependency Structure Language Model)模型代替传统的一元或二元模型,并将时间信息添加进模型中来增加新闻与相应话题之间相似度的准确性。Lee(2007)等人提出了针对互联网环境下论坛网页的方法,通过设置两层选择框架综合考虑文本间的相似度和用户的活跃度,来改善论坛网页中语言非正式带来的困难。
近年来,微博等平台也渐渐引起了国内学者的注意。如王政霄(2013)进行了微博热点事件挖掘和情感分析的研究,虽然完成了事件抽取的基本步骤,但是模型过于简单,难以应对实际需求;李博(2010)年针对网页数据,提出向量空间两次聚类的方法进行热点事件挖掘,但是没有深入考虑事件本身的结构特征,而且网页数据与web 2.0平台仍然有很大的差别;高金菊(2013)学习了Ritter(2012)等的方法进行中文微博的事件抽取,但是只是单纯地模仿英文系统的方法,并没有将中文的特点加入到模型中。
从以上文献分析中可以看到,现阶段事件挖掘技术已经有了基本的框架体系,但具体技术发展还不能够完全达到实际的需要。尤其是互联网的发展使数据量迅速上升,且包含很多噪音,给信息的抽取和处理造成了很大的困难。上述的方法虽然有很多在测试中达到了很好的效果,但它们主要应用于历史积累的文本如新闻报道,这类文本的质量很好,结构清晰,但是一旦将这些方法应用到互联网的海量信息如微博中,表现就会显著降低。由于中文与英文之间的巨大差异,使中文的处理和抽取面临很大的困难。因此英文系统的简单移植并不能解决中文自然语言处理问题,必须要针对中文的特点开发相应的方法,才能使问题得到解决。
本课题立足于互联网新媒体,选择中文微博作为目标平台,试图从微博的海量数据中抽取事件信息。我们结合已有的关于中文自然语言处理的研究和英文系统所使用的模型方法,开发出能在中文微博环境下达到较高效果的事件抽取工具,拓宽了中文事件挖掘的研究范围,进行了方法的创新。
3. 数据准备
本项目研究的数据来自新浪微博平台。在数据爬取过程中,本项目以“事故”作为关键词对新浪微博的微博数据进行搜索,利用爬虫软件对微博进行爬取,共获取包含“事故”关键词的微博16万余条。
对数据的观察结果显示,以“事故”为关键词爬取得到的新浪微博文本数据重复度较高,需要将其中重复的微博文本去掉,在本项目中,我们采取的是先去除微博干扰要素再去重的方法对微博文本进行预处理。
1. 去除微博干扰要素 微博中的要素对微博文本的去重工作起到了干扰的要素,需要将这些要素识别出来并进行去除。这些要素包括:1.话题或标题;2.@的用户;3.url;4.签到信息。
2. 文本去重。通过比较两篇文本的相似度,当相似度高于95%时,剔除其中一篇文本;当相似度不超过95%时,对两篇文本不做处理。取相似度为95%作为筛选标准是基于以下两个方面的考虑:由于数据进行了预处理,处理后的文章基本完全相同,所以取相似度较高;由于事故内容的关键字基本都是车祸、撞击之类,如果相似度太低,可能会剔除掉错误的内容。因此0.95作为相似度标准是实验结果最理想的去重效果。
通过去除微博干扰要素和去重算法,去除了52.9%的冗余信息。处理前,共包含163477条数据,处理后,包含76925条数据,去除了52.9%的重复微博,去重效果很明显。
在分词与词性标注方面,我们采用ICTCLAS(Institute of Computing T echnology, Chinese Lexical Analysis System)系统,利用层叠马尔科夫模型,进行分词与词性标注。处理过程如图1所示:
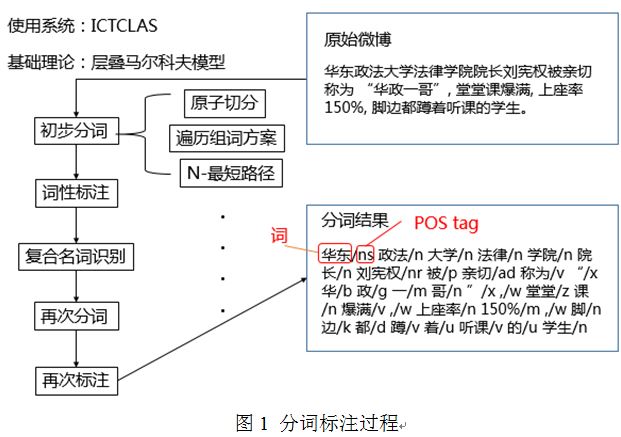
4. 微博事件信息抽取
对微博数据中的信息要素进行提取是分析微博事件新闻价值的准备工作,在这一步中,我们将抽象的文本信息转化成可量化可处理的数字信息。信息抽取完成之后,根据事件触发词、命名实体、时间表达和事件后果四类信息,作为后续工作的数据基础。
4.1 事件触发词及命名实体识别
在事件触发词及命名实体识别方面,我们主要应用条件随机场(conditional random field,简称CRF)模型设计信息抽取工具。通过对相应要素的标注、CRF模型的训练及对模型的反复调整来识别出微博文本中的事件触发词及命名实体要素。
项目利用基于条件随机场(conditional random field,简称CRF)对信息进行抽取,条件随机场结合分词信息、词性、上下文等特征进行模型训练,符合本项目的数据需求。首先需要对模型进行训练,在研究中,本项目采用的是通过人工标注得到训练样本,对训练样本进行训练得到标注模型。我们以事件触发词的抽取为例:
通过对已分完词中微博数据的事件关键词进行标注,本项目首先对76925条微博数据进行随机抽样,得到6000余条微博数据,采用人工标注的方式,对微博文本中的关键词进行标注。
在人工标注得到的6000余条微博分词文本的数据基础上,利用条件随机场工具,通过10折交叉验证的方法,得到了事件触发词的抽取模型。模型的测试结果如表1所示。

本研究 Baseline(Ritter et al., 2012)
召回率 62% 56%
准确率 72% 74%
F值 67% 64%
从模型的交叉验证结果可以看到,模型的召回率较高,准确率略低,F值比标准高,模型总体效果理想。
4.2 时间信息识别
在时间表达这一信息里,我们采用三个步骤对时间信息进行抽取,分别是正则表达式识别、不完整时间推理及规范化表示,其步骤过程如图2所示:
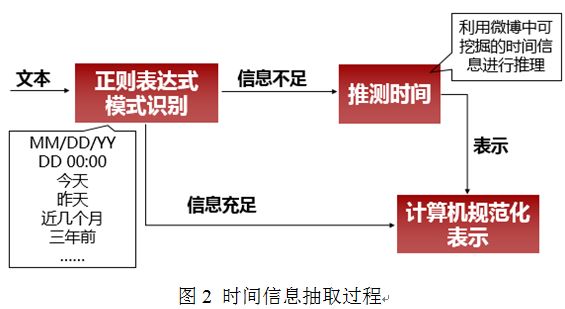
通过上图的步骤,我们将时间要素进行了规范化的处理,使其在成为后续模型构建过程中得以利用起来。我们当前设计了20多种时间识别模式,并且该方法可以随时扩添加新的识别模式,具有很好的扩展性。目前在测试中,时间表达抽取的准确率达到了90%以上。
4.3 事件后果识别
在事件后果抽取方面,本研究参考《基于规则匹配的突发事件结果信息抽取研究》(蒋德亮,2010)一文中的算法,结合本项目实际情况改进而成。该算法分为如下几个步骤:
事故后果正则匹配,初步抽取。根据对采集的数据统计观察,研究文本句式特点,根据以下收集的关键词,归纳并建立正则表达式,从而对文本中的事故后果信息进行初步匹配和抽取。
构建结果信息节点。将初步抽取的事故后果信息存放在适当的数据结构中以便进行后续处理。该数据结构主要包括以下几个属性:
Result:伤亡后果
StartPositon:事故后果信息在文本中的开始位置
EndPositon:事故后果信息在文本中的结束位置
Count:伤亡后果的损失数
Deep:结构深度
节点信息规范化。对结果节点信息进行规范化处理,以便后续进行处理,具体分为结果类型规范化、数量单位规范化和数字规范化三类。
节点之间包含关系处理。根据两节点之间的相对包含关系以及如下规则,设定各个节点的结构深度,从而构建结构树图。
根据各个结果类型的结构树图,找出其中结构深度最大的节点群,将其Count值进行累加,得出该类型最终结果。
5. 可视化结果展示
本系统采用JAVA编程语言实现,通过搭建struts2框架完成系统的基本信息交互处理。前端采用bootstrap框架进行页面展示,同时调用d3.js库实现对数据的可视化展示。效果展示如图3所示:
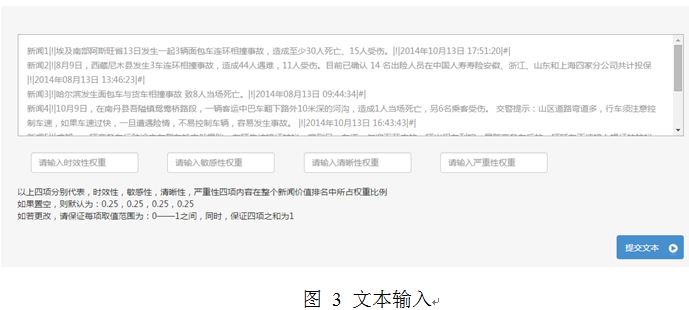
在上方输入框中输入文本,文本格式为:新闻标题|!|新闻内容|!|发布时间|#|
本研究通过可视化处理将内容实现了多个功能模块的展示,分别是:词性分析、命名实体抽取结果、敏感词抽取和事故信息抽取。其展示界面如图4-图7所示。

根据右侧词性类别图示,将文本进行分词,并根据词性不同,将分词结果以不同颜色展示出来。

根据右侧命名实体类别图示,对文本进行命名实体抽取,并将结果以不同颜色展示出来。

根据右侧敏感程度级别图示,对文本进行敏感词抽取,并将结果以不同颜色展示出来。
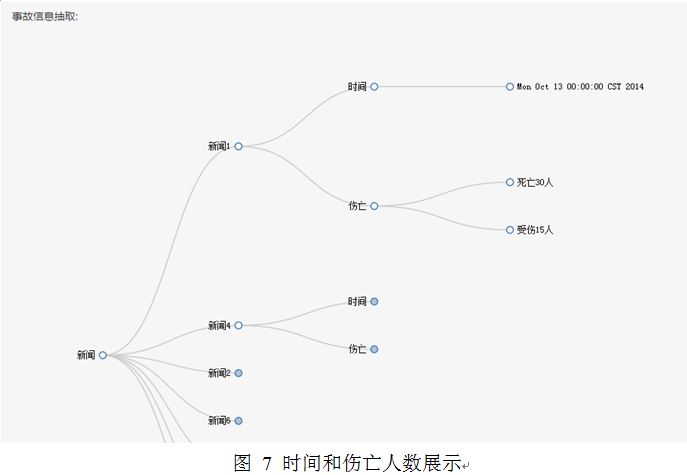
分别对文本进行新闻发生时间及事故后果信息抽取,并将抽取结果以树图形式展示。
6. 总结与讨论
本研究通过人工标注的方法,对100个新闻事件进行了信息的提取,同时运用本研究的成果对这100个新闻事件进行处理。通过实际结果与模型结果的比对,本研究的信息提取结果能达到85%的准确率,基本实现了事件的新闻要素信息提取。接下来的研究方向是对算法进行改进,进一步提高信息提取结果的准确率。
本研究的成果有助于新闻媒体高效地发现网络事件的新闻线索,提高获得新闻的速度与质量,对于新闻媒体来说同样具有现实意义。
参考文献
[1] James Allan, Jaime Carbonelly, George Doddingtonz, et al. Topic Detection and Tracking Pilot Study Final Report[J]. Proceedings of the Darpa Broadcast News Transcription & Understanding Workshop, 1998:194--218.
[2] Lam W, Meng H M L, Wong K L, et al. Using contextual analysis for news event detection[J]. International Journal of Intelligent Systems, 2001, 16(4):525-546.
[3] Yang Y, Carbonell J, Brown R, et al. Multi-strategy Learning for Topic Detection and Tracking[J]. Information Retrieval, 2002.
[4] Kumaran G, Allan J, Mccallum A. Classification models for new event detection[J]. University of Massachusetts - Amherst, 2004.
[5] Brants T, Chen F, Farahat A. A System for new event detection.[J]. Sigir Proceedings of Annual International Acm Sigir Conference on Research & Developm, 2003:330-337.
[6] Waltinger U, Mehler A, Heyer G. Towards automatic content tagging: Enhanced web services in digital libraries using lexical chaining[J]. in 4th International Conference on Web Information Systems and Technologies (WEBIST ’08, 2008:231--236.
[7] Ghrist R. Barcodes: The persistent topology of data[J]. Bulletin of the American Mathematical Society, 2008, 45(1):61-75.
[8] Petrovi? S, Osborne M, Lavrenko V. Streaming first story detection with application to Twitter[J]. Human Language Technologies the Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2010.
[9] Hovy E, Metzler D, Cai C. Structured Event Retrieval over Microblog Archives[J]. In NAACL-HLT, 646–655, 2012.
[10] Ritter A, Mausam,, Etzioni O, et al. Open domain event extraction from twitter[C]// Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data miningACM, 2012:1104-1112.
[11] 张阔, 李涓子, 吴刚,等. 基于词元再评估的新事件检测模型[J]. 软件学报, 2008, 19:817-828. DOI:doi:10.3724/SP.J.1001.2008.00817.
[12] 洪宇, 张宇, 范基礼,等. 基于语义域语言模型的中文话题关联检测[J]. 软件学报, 2008, 19:2265-2275.
[13] Wang H C, Huang T H, Guo J L, et al. Journal Article Topic Detection Based on Semantic Features[M]// Next-Generation Applied IntelligenceSpringer Berlin Heidelberg, 2009:644-652.
[14] Qiu J, Liao L, Dong X. Topic Detection and Tracking for Chinese News Web Pages[C]// Advanced Language Processing and Web Information Technology, International Conference onIEEE, 2008:114-120.
[15] Lee, Sang‐Ki. Effects of Textual Enhancement and Topic Familiarity on Korean EFL Students' Reading Comprehension and Learning of Passive Form[J]. Language Learning, 2007, 57(1):87-118.
[16] 王政霄, 黄征. 一种中文微博观点抽取技术[J]. 信息安全与通信保密, 2013, 01期:49-50. DOI:doi:10.3969/j.issn.1009-8054.2013.01.023.
[17] 李博. 网络热点事件挖掘及特征描述研究[D]. 国防科学技术大学, 2010. DOI:doi:10.7666/d.d138970.
[18] 高金菊. 微博开放领域的事件抽取[D]. 中山大学, 2013.
[19] 蒋德良. 基于规则匹配的突发事件结果信息抽取研究[J]. 计算机工程与设计, 2010, 第14期:3294-3297.
(此文不代表本网站观点,仅代表作者言论,由此文引发的各种争议,本网站声明免责,也不承担连带责任。)
